An Architecture for LLM-Database Integration
August 27, 2025Note: This article is part of our ongoing exploration of AI systems and architectures. You can find more articles in this series at /ai. This essay emerged from collaborative discussions about LLM-database integration architecture, with AI systems contributing to content development, code examples, and architectural analysis.
Introduction
Modern digital systems are built upon diverse data storage technologies that serve different architectural needs. While document databases like MongoDB dominate many startup environments due to their flexibility and ease of implementation, graph databases power social networks and recommendation systems, key-value stores handle high-throughput caching, and time-series databases manage IoT and monitoring data. However, relational databases remain the backbone of most enterprise systems and production applications, with frameworks commonly defaulting to PostgreSQL or MySQL for their ACID compliance, mature tooling, and well-understood operational characteristics.
These databases, regardless of their underlying architecture, share a common challenge: they store data in structured formats optimized for machines, not human communication. A MongoDB collection storing customer orders uses field names like “cust_id” and “ord_status” that reflect technical convenience rather than business meaning. A PostgreSQL schema organizing student data across enrollment, attendance, and grade tables requires understanding of normalization principles and join semantics that business users shouldn’t need to master.
People express their needs through intent, not technical specifications. A school principal asks, “Which students in Mr. Johnson’s mathematics classes have missed more than three sessions this semester?” A retail manager inquires, “Show me customers who purchased product A but returned product B within thirty days.” These questions reflect business objectives expressed in domain vocabulary, not data structure navigation commands.
Large Language Models offer a promising bridge between natural language intent and structured data operations. However, directly connecting LLMs to data systems creates serious architectural problems. Beyond the obvious issues of fabricated table names and incorrect join logic, there are fundamental concerns about data privacy and system scalability. Sending entire datasets or database contents to external LLM providers exposes sensitive information and violates most organizational data governance policies. Moreover, LLMs perform poorly when overwhelmed with excessive context, struggling to identify relevant information within large data dumps.
The solution requires an architectural approach that teaches models about data structures through semantic abstraction rather than raw exposure, enables understanding of complex multi-step operations beyond simple queries, and maintains strict control over data privacy and system resources. While this essay focuses on relational database integration as a comprehensive example, these architectural patterns apply equally to any structured data system, from document stores to graph databases to specialized analytical platforms.
Core Idea
The foundational principle that drives successful LLM database integration addresses two critical architectural concerns: data privacy and semantic understanding. Many projects attempt direct data exposure, sending entire datasets or database contents to LLMs with prompts like “analyze this customer data and find patterns.” This approach fails on multiple levels: it violates data governance policies by exposing sensitive information to external services, overwhelms models with excessive context that degrades their reasoning capabilities, and provides no structured framework for reliable query construction or validation.
The solution centers on creating an intermediary semantic layer that translates database structures into comprehensible concepts without exposing actual data. This semantic layer, the Schema Wrapper, serves as an intelligent abstraction that teaches models about data relationships, business rules, and domain vocabulary while maintaining strict data privacy boundaries. The LLM never sees customer records, student grades, or financial transactions. Instead, it reasons about semantic descriptions of what those records represent and how they relate to each other.
This approach extends beyond simple query generation to support complex multi-step operations. The system must understand whether a user wants to read data (“show me failing students”), write data (“update Sarah’s grade to A”), execute external actions (“send reminder emails to absent students”), or orchestrate workflows (“generate report and email to department heads”). Each intent type requires different processing paths, validation rules, and safety mechanisms.
The wrapper enables semantic query understanding rather than brittle rule-based matching. Instead of hardcoded patterns that break when users rephrase requests, the system develops contextual understanding of domain concepts. When a user asks about “at-risk students,” the system consults the wrapper to understand that this concept encompasses multiple indicators: low GPA, high absence rates, incomplete assignments, and behavioral flags. It then constructs appropriate queries that combine these factors according to institutional definitions, rather than guessing at what “at-risk” might mean.
This architectural foundation scales across any data storage technology. While relational databases provide our primary example due to their ubiquity in enterprise systems, the same wrapper principles apply to document stores, graph databases, time-series systems, and hybrid architectures. The semantic abstraction layer adapts to different data models while maintaining consistent interfaces for natural language interaction.
Architecture
The architecture consists of multiple interconnected layers, each responsible for a specific aspect of the translation process from natural language intent to reliable database results.
High-Level System Architecture
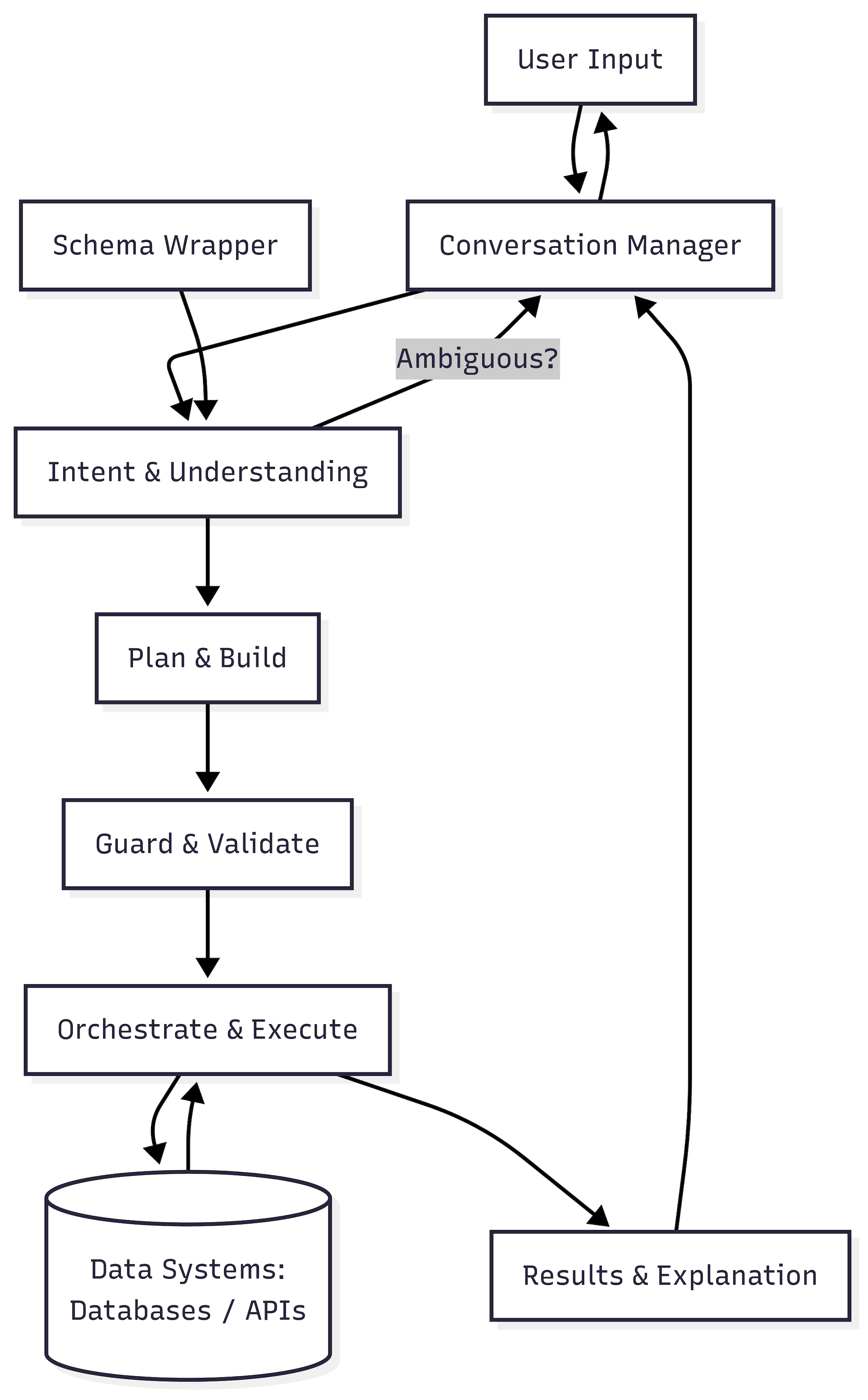
Figure 1: High-level system architecture showing the core components and data flow from user input through the Schema Wrapper to database results and external system interactions.
Detailed Component Architecture
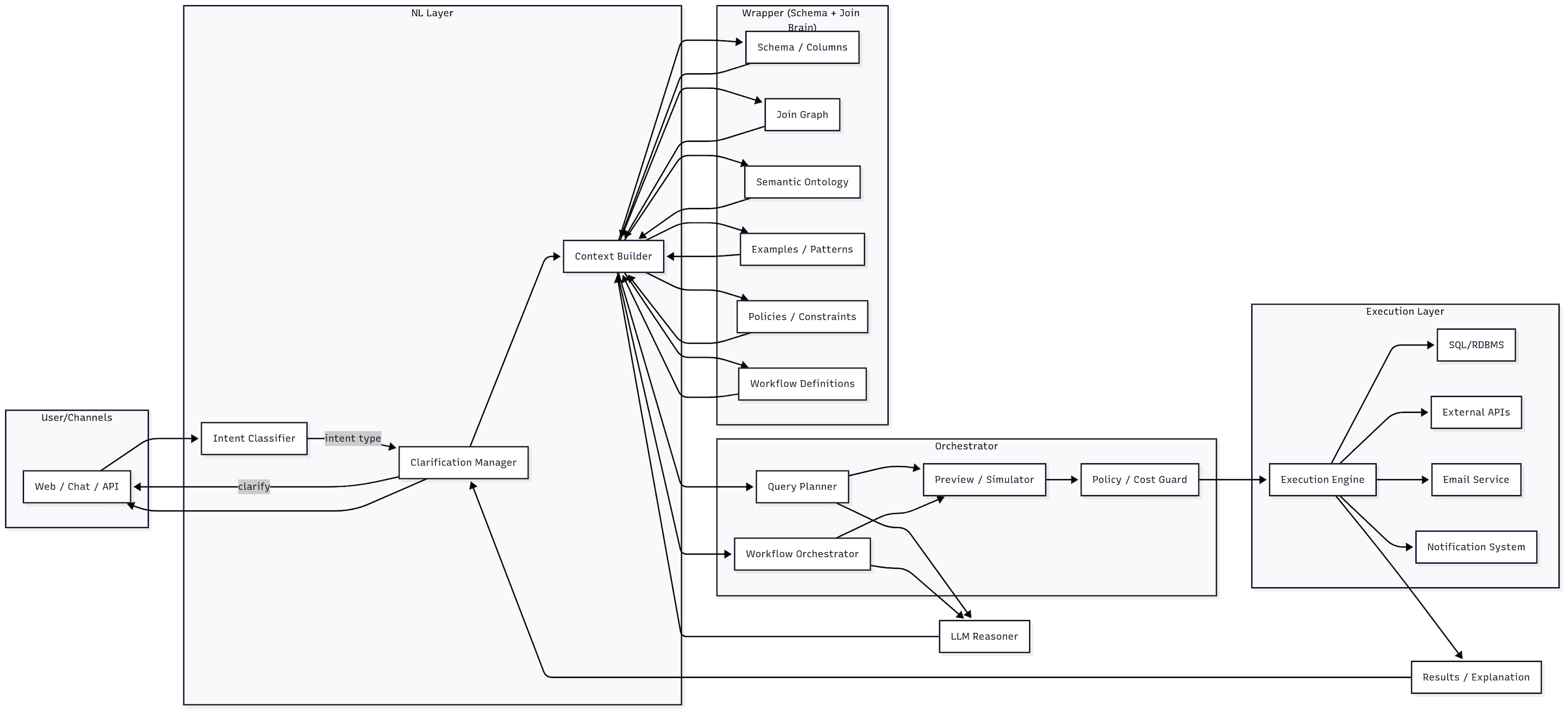
Figure 2: Detailed component architecture illustrating the Natural Language Layer, Orchestrator, LLM Reasoner, Schema Wrapper subsystems, Execution Layer, and Observability components with their interconnections.
Interaction Flow Sequence
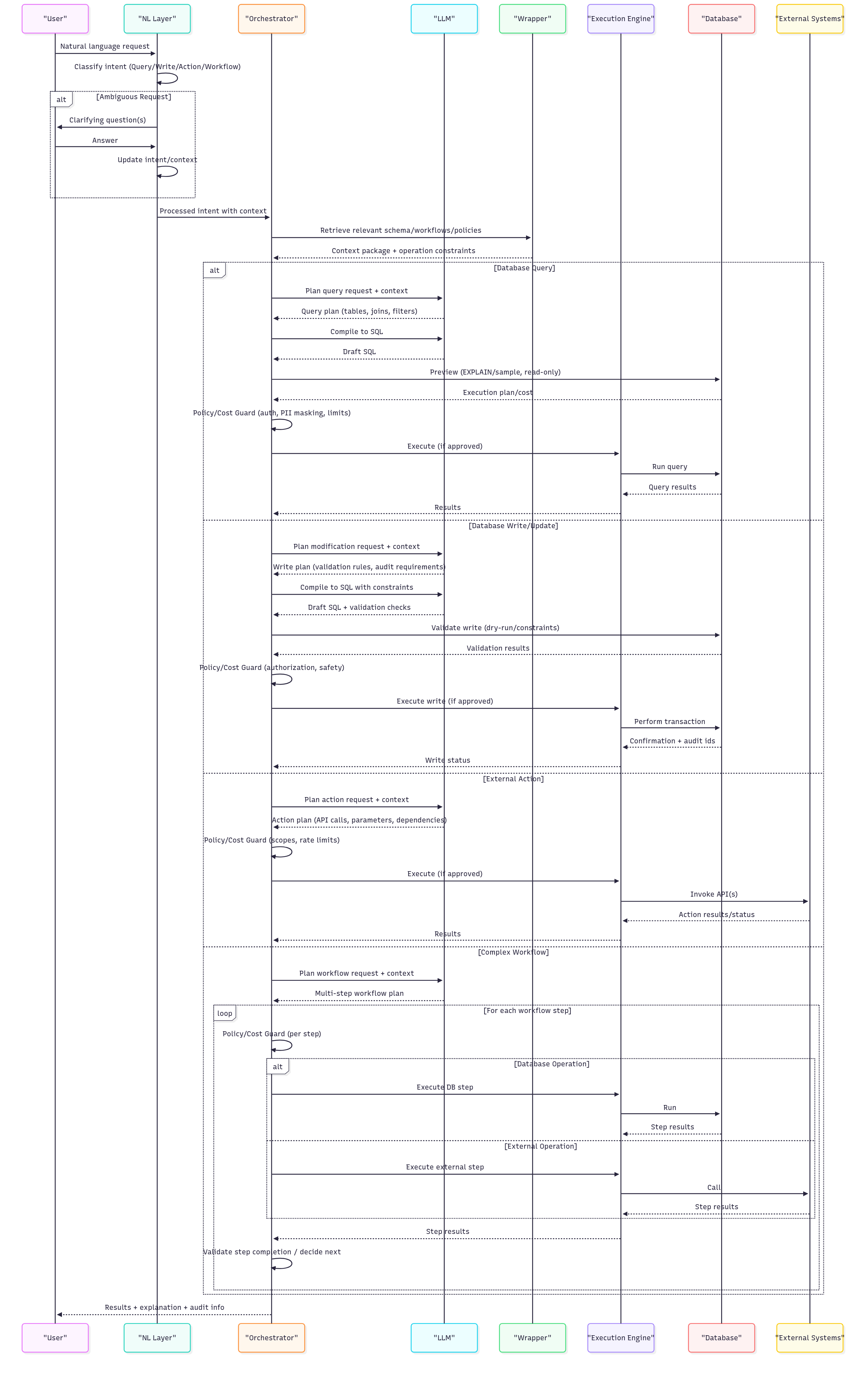
Figure 3: Interaction flow sequence diagram showing the step-by-step process from user request through intent classification, schema retrieval, and execution for different operation types (queries, writes, actions, and workflows).
Complete Processing Flow
The system processes natural language requests through a structured pipeline that branches based on intent type, ensuring appropriate handling for queries, writes, actions, and workflows:
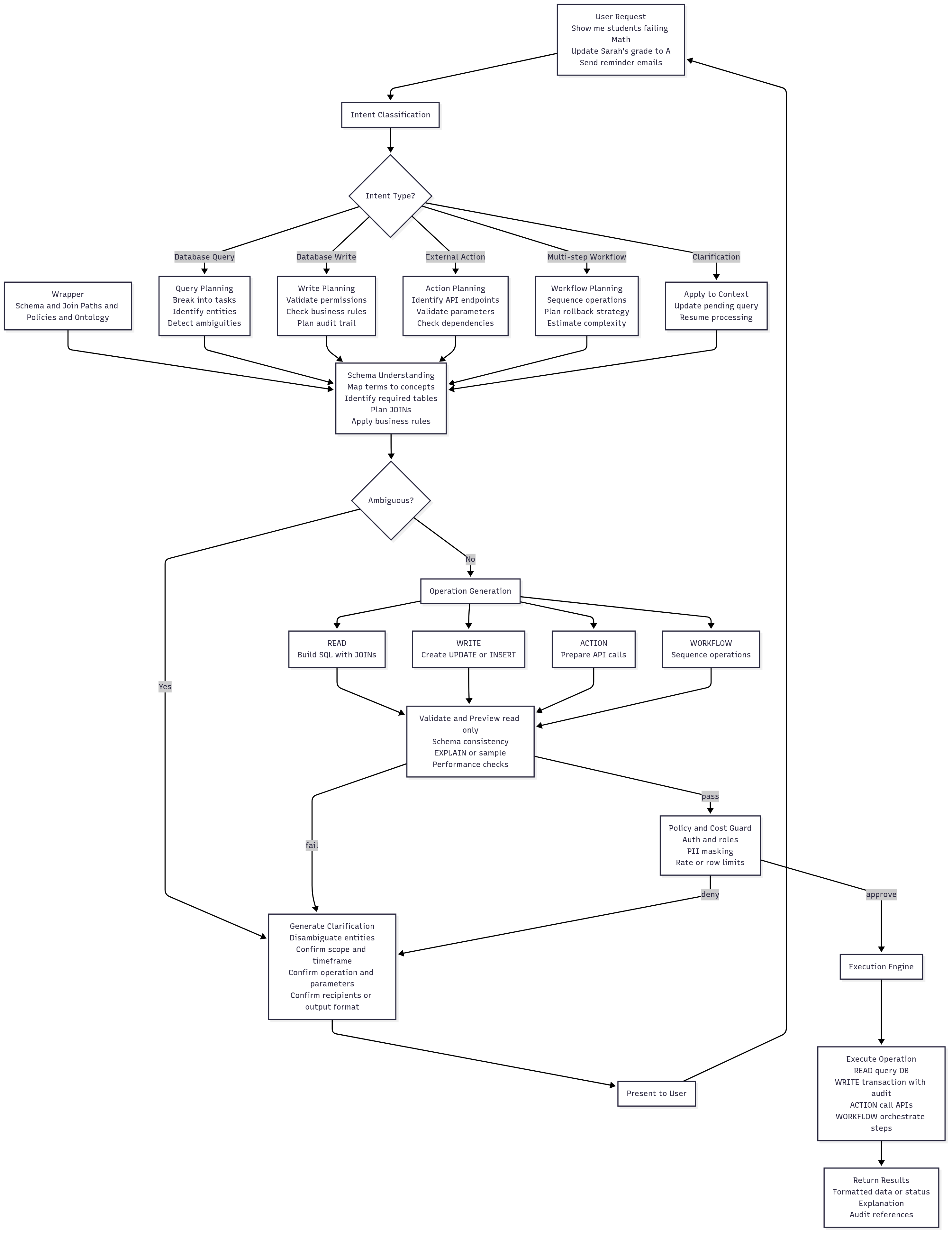
Figure 4: Complete processing flow diagram demonstrating the branching pipeline that handles different intent types, from initial classification through schema understanding, operation generation, validation, and execution.
The User Input layer accepts diverse natural language requests through web applications, chat interfaces, and API endpoints. This layer handles not only traditional data queries like “Show me failing students” but also database modification commands such as “Update Sarah’s grade to A,” external action requests like “Send reminder emails to absent students,” and complex workflow instructions such as “Process end-of-semester procedures: finalize grades, generate transcripts, and notify advisors.”
The Conversation Manager maintains contextual state across multiple interaction turns for all operation types. It understands that “now update their grades” refers to the student cohort from a previous query, or that “send the report we just generated” connects to a recently completed data analysis. This context preservation is particularly crucial for multi-step workflows where users may want to modify, approve, or cancel operations in progress.
The Intent Classifier performs the crucial first analysis step, determining whether incoming text represents a database query request, database modification command, external action trigger, workflow orchestration request, or clarification response to a previous system question. Each intent type requires different processing pathways: queries need read optimization, writes require authorization and audit trails, actions need API validation, and workflows require step sequencing and rollback planning. Accurate intent classification prevents system confusion and ensures that each input type receives appropriate processing.
The Schema Wrapper serves as the central intelligence repository, containing rich semantic descriptions of database structures, canonical join paths between related entities, write operation validation rules, API endpoint specifications, workflow step definitions, domain specific vocabulary and synonyms, example operations across all types, and comprehensive policy rules that govern safe data access, modification permissions, and external system interactions. The wrapper provides contextually relevant information to guide query planning, write validation, action preparation, and workflow orchestration.
The Schema Understanding component maps natural language terms to specific database entities, API parameters, and workflow steps using the wrapper’s semantic information. It identifies which tables and columns are relevant to reads or writes, determines appropriate join strategies or modification sequences, detects potential ambiguities across all operation types that may require user clarification, and loads the appropriate validation rules and policies for each operation category.
The Query Planner decomposes complex requests into manageable sequential steps, handling not only queries that span multiple tables but also write operations that require validation sequences, API calls that depend on data retrieval, and workflows that orchestrate multiple systems. The planner creates execution strategies for reads, writes, external actions, and multi-step processes that can be validated and optimized before any system interaction occurs.
The Query Builder and Optimizer construct operations using proven patterns from the wrapper’s canonical libraries. For database reads, it builds SQL statements with optimized joins and performance considerations. For writes, it creates UPDATE/INSERT/DELETE statements with integrity checks and audit trail requirements. For external actions, it prepares API calls with proper authentication, parameter validation, and error handling. For workflows, it sequences operations with dependency management, rollback capabilities, and state tracking.
The SQL Compiler and Validator perform comprehensive safety checks across all operation types, confirming that operations reference valid schema elements and respect access control policies. The compiler applies wrapper patterns to construct SQL statements, API calls, or workflow sequences with appropriate safety mechanisms. Operations that fail validation are rejected before reaching any external system.
The Execution Engine orchestrates validated operations across database systems, external APIs, notification services, and workflow management platforms. For database operations, it handles transactions with rollback capabilities. For API interactions, it implements retry logic, timeout handling, and rate limiting. For workflows, it maintains state between steps and can pause for user approval or external system availability. This component formats results appropriately for each operation type and generates explanations of what was executed and why.
Schema Wrapper
The Schema Wrapper represents the most critical architectural component, serving as the repository of domain intelligence that enables successful LLM database integration. The wrapper transforms opaque database structures into meaningful knowledge that both humans and models can understand and utilize effectively.
Consider the difference between a raw database table definition and its wrapper equivalent. A typical enrollment table might be defined as follows:
CREATE TABLE enrollments (
enrollment_id INT PRIMARY KEY,
student_id INT,
class_id INT,
status VARCHAR(20),
enrollment_date DATE,
withdrawal_date DATE
);
Example 1: Traditional database table definition showing raw technical structure without business context or semantic meaning.
This definition provides technical structure but offers no insight into business meaning, usage patterns, or contextual relationships. The wrapper transforms this technical specification into rich semantic knowledge with comprehensive business context:
enrollments: {
description: "Student registration records for specific class sections",
businessPurpose: "Tracks which students are enrolled in which classes and their participation status",
columns: {
status: {
type: "enum",
description: "Current enrollment state indicating student participation level",
values: {
"Active": "Student is currently attending and participating in the class",
"Withdrawn": "Student has officially dropped the class",
"Completed": "Student has successfully finished the class",
"On_Hold": "Student enrollment is temporarily suspended"
},
businessRules: "Only Active enrollments should appear in current class rosters",
queryPatterns: "Filter by status='Active' for current students"
},
enrollment_date: {
type: "date",
description: "Date when student was registered for the class",
businessRules: "Must be within the academic term date range",
commonFilters: "enrollment_date >= term_start_date"
}
},
relationships: {
to_students: {
type: "many_to_one",
joinPath: "enrollments.student_id = students.student_id",
description: "Each enrollment record belongs to exactly one student",
businessMeaning: "Links enrollment records back to student demographic and academic information"
},
to_classes: {
type: "many_to_one",
joinPath: "enrollments.class_id = classes.class_id",
description: "Each enrollment is for a specific class section",
businessMeaning: "Connects students to the specific class sections they are taking"
}
},
commonQueries: [
"Active enrollments for a specific class section",
"All enrollments for a particular student across terms",
"Enrollment counts by status for reporting"
],
synonyms: {
"registration": "enrollment",
"class_roster": "active enrollments for a class",
"student_schedule": "active enrollments for a student"
}
}
Example 2: Schema Wrapper semantic definition transforming the raw table structure into rich business intelligence with relationships, rules, and domain vocabulary.
The wrapper contains five distinct categories of information that work together to provide complete domain context:
• Schema Intelligence: Captures the technical structure including tables, columns, data types, primary keys, foreign keys, and indexes. This foundational layer ensures that generated queries reference valid database objects and utilize optimal access paths for performance.
• Join Graph Documentation: Documents canonical relationships between entities, specifying not just that tables can be connected, but how they should be connected for different business purposes. A student’s academic performance, for example, might be accessed through multiple possible join paths, but only certain combinations respect business rules about active enrollments, current terms, and valid grade records.
joinPaths: {
"student_to_grades": {
canonical: "students → enrollments → classes → assignments → grades",
path: [
{ from: "students.student_id", to: "enrollments.student_id" },
{ from: "enrollments.class_id", to: "classes.class_id" },
{ from: "classes.class_id", to: "assignments.class_id" },
{ from: "assignments.assignment_id", to: "grades.assignment_id" }
],
businessLogic: "Only include Active enrollments and current term classes",
filters: [
"enrollments.status = 'Active'",
"classes.term_id = current_term()"
],
description: "Standard path to get student grades with proper filtering",
alternatives: {
"direct_via_grades": {
path: "students → grades (via student_id)",
when: "grades table has denormalized student_id",
risk: "May include historical grades from withdrawn classes"
}
}
},
"student_to_attendance": {
canonical: "students → enrollments → classes → attendance_events",
path: [
{ from: "students.student_id", to: "enrollments.student_id" },
{ from: "enrollments.class_id", to: "classes.class_id" },
{ from: "classes.class_id", to: "attendance_events.class_id" },
{ from: "students.student_id", to: "attendance_events.student_id" }
],
businessLogic: "Cross-reference enrollment and attendance for accuracy",
filters: [
"enrollments.status = 'Active'",
"attendance_events.event_date >= enrollments.enrollment_date"
],
description: "Ensures attendance records match current enrollments"
}
}
Example 3: Join path configuration defining canonical relationships between entities with business logic filters and alternative access patterns.
• Semantic Ontology: Maps domain vocabulary to database structures, enabling the system to understand that “class roster” refers to active enrollments for a specific class section, that “academic performance” encompasses grades and assignment completion, and that “at risk students” involves calculations based on attendance, grades, and assignment submission patterns.
• Example Query Library: Serves multiple purposes within the wrapper ecosystem. These examples provide patterns that guide query construction, demonstrate proper join usage and filter application, and serve as regression tests that ensure system stability as components evolve. Each example includes the natural language request, the business logic reasoning, and the resulting SQL with explanations of key decisions.
• Policy Enforcement Rules: Ensure that the system operates within organizational and regulatory constraints. These policies specify which data can be accessed by different user roles, what masking should be applied to sensitive information, what resource limits constrain query execution, and which operations are prohibited entirely.
Intent
Intent classification serves as the critical first decision point that determines how the system processes each user input. Accurate classification prevents costly errors and ensures that different input types receive appropriate handling through specialized processing paths. Modern systems must recognize not only query requests but also action commands, workflow triggers, and hybrid operations that combine multiple system capabilities.
The system recognizes five primary intent categories, each requiring distinct processing strategies:
• Data Query Requests: Traditional information retrieval operations such as “Show me students who are failing mathematics courses” or “Find customers who purchased more than $500 last month.” These inputs trigger the schema understanding and query planning pipeline, focusing on efficient data retrieval with appropriate filtering, joining, and aggregation operations.
• Data Modification Commands: Write operations that alter system state, including “Update Sarah’s grade to A in Calculus” or “Mark John as withdrawn from Chemistry class.” These operations require additional validation layers, audit trail generation, and often approval workflows before execution. The system must understand not just what data to change but also business rule compliance and cascading effects.
• External Action Triggers: Commands that invoke operations beyond database interaction, such as “Send reminder emails to students with missing assignments” or “Generate and email attendance report to department heads.” These intents require integration with external systems, template processing, and often user confirmation before execution.
• Workflow Orchestration: Complex multi-step operations like “Process semester-end grade finalization: calculate GPAs, generate transcripts, update student status, and notify advisors.” These requests require breaking complex business processes into sequential steps with appropriate validation, rollback capabilities, and progress tracking.
• Clarification Responses: User responses to system questions during ambiguity resolution, which must be matched against pending clarification contexts and integrated with existing query or action plans.
Semantic Query Understanding
The system moves beyond simple rule-based pattern matching to develop contextual understanding of domain concepts. Traditional approaches fail when users rephrase requests or combine concepts in unexpected ways. A rule-based system might recognize “failing students” but struggle with “students at academic risk” or “pupils with concerning performance trends.”
Semantic understanding enables the system to handle complex, multi-faceted requests:
User: "Show me students who are struggling academically and might need intervention"
Traditional Pattern Matching:
- Fails to recognize "struggling academically"
- No predefined rule for "might need intervention"
- System error or generic clarification request
Semantic Understanding:
- Maps "struggling academically" to wrapper concepts: low GPA, missing assignments, poor attendance
- Understands "intervention" relates to academic support programs
- Constructs query combining multiple risk indicators
- Offers clarification about "intervention" criteria if needed
Example 4: Comparison between rule-based pattern matching and semantic understanding approaches for handling complex, multi-faceted user requests.
The wrapper enables this semantic understanding by encoding concept relationships, synonym mappings, and business rule interconnections. When the system encounters “struggling academically,” it consults the wrapper to understand this encompasses multiple measurable factors, each with specific thresholds and weighting in the overall assessment.
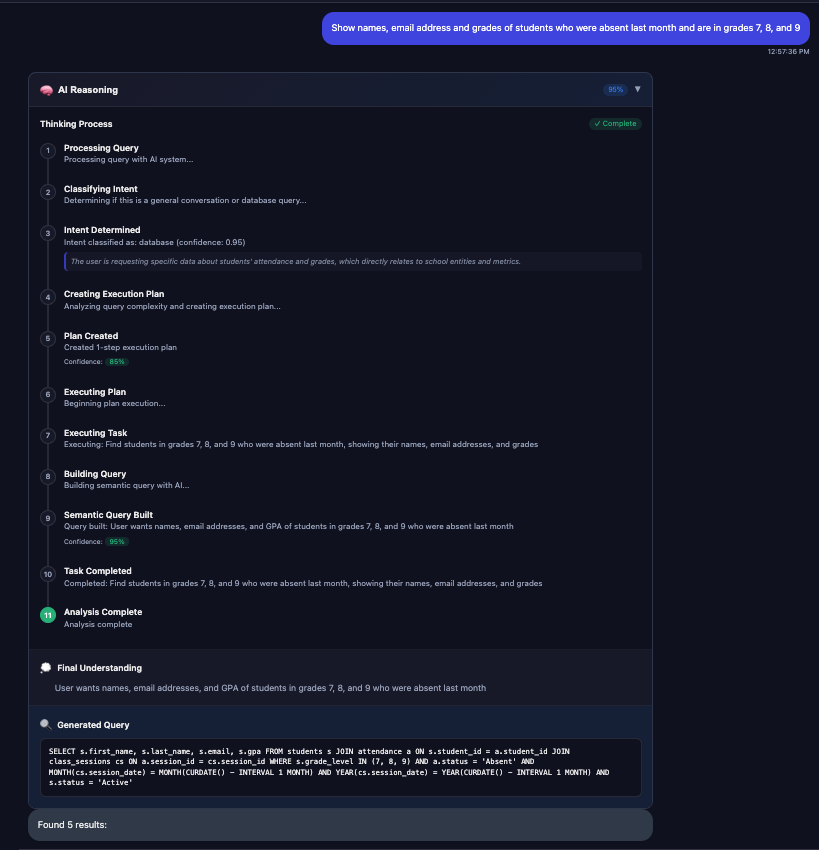
Figure 5: Proof of concept demonstration showing semantic query understanding in action, where natural language requests are processed through the wrapper to generate appropriate database operations.
Multi-Step Action Processing
Complex user intents often require orchestrating multiple operations across different system components:
User: "Process grade changes for Math 101: update final grades, recalculate GPAs, and notify affected students"
Processing Steps:
1. Parse intent: Grade modification workflow
2. Identify scope: Math 101 course
3. Validate permissions: User authorized for grade changes
4. Plan sequence: Update grades → Calculate GPAs → Send notifications
5. Execute with rollback: Each step validates before proceeding
6. Audit trail: Record all changes and notifications sent
Example 5: Multi-step action processing workflow showing how complex user intents are decomposed into sequential operations with proper validation and rollback mechanisms.
The system must understand dependencies between operations, potential failure points, and appropriate recovery mechanisms. Grade updates must complete successfully before GPA recalculation, and notification sending should not prevent the academic changes if email systems are unavailable.
Write Operation Examples
Beyond traditional queries, the system handles data modification with appropriate validation and business rule enforcement:
User: "Update Sarah Chen's grade in Calculus to B+ and add a note about improvement"
Write Processing:
1. Intent: Database modification command
2. Entity Resolution: Identify specific student and course
3. Permission Check: Verify grade modification authority
4. Business Rules: Validate grade within acceptable range
5. Audit Preparation: Log original values before change
6. Transaction Execution: Update grade and add note atomically
7. Cascade Updates: Trigger GPA recalculation if needed
8. Confirmation: Return success status with audit reference
Example 6: Write operation processing flow demonstrating the additional validation, permission checking, and audit trail requirements for database modifications.
Write operations require additional safeguards including transaction management, audit trail creation, and cascade effect handling that simple queries do not need.
Workflow Orchestration Examples
Complex business processes involve multiple steps across different systems:
User: "Execute semester transition: archive current grades, promote students to next level, generate transcripts, and email parents"
Workflow Execution:
1. Workflow Planning: Break into sequential tasks with dependencies
2. Resource Validation: Check system availability and permissions
3. Step 1: Archive grades (database operation)
- Validate: All grades finalized
- Execute: Move to historical tables
- Verify: Archive integrity check
4. Step 2: Student promotion (database + business logic)
- Calculate: Promotion eligibility
- Update: Student status and class assignments
- Validate: Enrollment capacity constraints
5. Step 3: Transcript generation (report + file operations)
- Generate: PDF transcripts for promoted students
- Store: Documents in file system
- Index: References in database
6. Step 4: Parent notification (external API calls)
- Prepare: Email templates with student data
- Send: Batch email via notification service
- Track: Delivery status and failures
7. Completion: Workflow status summary and error report
Example 7: Complex workflow orchestration showing multi-system operations with dependency management, state tracking, and comprehensive error handling.
Workflow orchestration requires state management, rollback capabilities, and progress tracking across multiple system boundaries.
Clarification
Ambiguity represents a natural characteristic of human language rather than a system failure to be eliminated. Successful architectures embrace ambiguity by transforming unclear requests into collaborative dialogue that guides users toward precision while maintaining engagement and trust.
Traditional systems often respond to ambiguity with generic error messages that provide little guidance and force users to guess about system requirements. A typical poor response might state “Your query is ambiguous, please provide more details” without indicating what specific information is needed or what options are available.
Effective clarification strategies generate specific, actionable questions that directly address the identified ambiguities:
// Bad: Generic clarification
"Your query is ambiguous. Please provide more details."
// Good: Specific, actionable questions
"I found 3 teachers named Johnson:
- Robert Johnson (Math Department)
- Sarah Johnson (English Department)
- Michael Johnson (Science Department)
Which teacher did you mean?"
Example 8: Clarification strategy comparison showing the difference between generic error messages and specific, actionable questions that guide users toward precision.
• Specific Entity Resolution: When a user asks about “students in Mr. Johnson’s class,” the system should recognize that multiple teachers named Johnson may exist and respond with concrete choices: “I found three teachers named Johnson: Robert Johnson teaching Algebra I, Sarah Johnson teaching English Literature, and Michael Johnson teaching Biology. Which teacher’s class are you asking about?”
• Business Rule Clarification: When terms have multiple valid interpretations within the domain, the system should present the alternatives clearly: “When you mention ‘failing students,’ I can interpret this as students with GPA below 2.0, students with multiple incomplete assignments, or students flagged for attendance issues. Which definition should I use?”
• Time Scope Resolution: Temporal references often require clarification: “For current semester data, should I include the entire fall semester or limit results to courses still in progress?”
The clarification process should minimize user effort while maximizing information gain. Each question should cut ambiguity significantly, avoiding lengthy interrogation sequences that frustrate users. When possible, the system should offer intelligent defaults based on context, user role, or common usage patterns while clearly indicating that alternatives are available.
Session state management ensures that clarification responses integrate smoothly with ongoing conversations. When a user provides clarification about teacher identity, that information should persist for follow up queries like “now show their attendance patterns” without requiring repetition of the clarification. The system maintains a coherent conversational thread while building cumulative understanding.
Clarification design should consider the broader user experience beyond individual query resolution. Well crafted clarifications teach users about system capabilities and data structures, gradually improving the quality of initial requests. Users learn to provide more specific information upfront when they understand what distinctions matter within the domain.
Once ambiguities are resolved through clarifications, the system moves into its reasoning phase. This is where intent, schema context, and policies are stitched together into a transparent decision process. Reasoning ensures that every query, write, workflow, or external action is not just executed, but explained, turning opaque black-box outputs into auditable, trustworthy steps.
Reasoning
Reasoning transparency distinguishes reliable production systems from brittle prototypes. Rather than behaving like a black box that mysteriously transforms questions into answers, the system exposes its decision-making process, building user confidence and enabling effective debugging when results do not meet expectations.
The reasoning process follows a structured sequence across all intent types:
• Intent Classification: Determines whether the input is a query, a write operation, an external API call, or a workflow orchestration. Routing the request correctly is the foundation for safe execution.
• Query Planning: Breaks complex requests into subtasks, identifying required data sources, joins, filters, and aggregations. For workflows, this includes sequencing multiple dependent steps. For API actions, this includes validating parameters and dependencies.
• Ambiguity Detection: Identifies where user intent might be unclear (names, time ranges, criteria) and prompts for clarification before proceeding.
• Schema and Policy Resolution: Maps intent to specific tables, join paths, API endpoints, or workflow definitions, always consulting wrapper intelligence and enforcing business rules.
• Partial Context Delivery: To prevent LLM overload, the system employs ground slicing, providing only the relevant subset of schema, policies, or examples instead of the full wrapper. This ensures reasoning quality while respecting model token limits.
• Compilation and Validation: Translates the plan into SQL, API calls, or workflow steps using canonical patterns. Every operation undergoes validation for schema correctness, policy compliance, and resource limits.
• Execution Preview: When appropriate, the system runs cost checks, EXPLAIN queries, or dry-run simulations to validate efficiency and safety before execution.
The reasoning trace itself becomes part of the output: “I interpreted failing students as GPA below 2.0 in the current term, identified mathematics courses from the catalog, joined active enrollments, and applied institutional filters.”
By surfacing these steps, reasoning not only improves trust but also feeds directly into the Observability Layer, enabling developers to diagnose errors, compare reasoning chains across queries, and continuously refine the wrapper.
Other Core Modules
Beyond the primary components of wrapper, intent classification, clarification, and reasoning, several additional modules provide essential functionality that enables reliable production operation of LLM database integration systems.
Conversation Manager
The Conversation Manager maintains contextual state across multiple interaction turns, enabling natural dialogue patterns. It resolves pronoun references like “their performance” to previously identified entities and understands action continuity such as “now update their status” referring to the same student cohort. For complex workflows, it tracks multi-step processes where users might modify, approve, or cancel operations in progress.
Query Planner
The Query Planner decomposes complex requests into manageable sequential steps, handling queries, write operations, API calls, and multi-step workflows. It creates execution strategies that consider task dependencies, optimize sequences for efficiency, and maintain intermediate results for meaningful analysis. For complex operations like “compare this quarter’s performance to last quarter for top students,” the planner breaks this into: identify top students, calculate current metrics, calculate previous metrics, and generate comparisons.
Observability Layer
The Observability Layer captures telemetry about every stage of this reasoning chain. Logs include user requests, clarification paths, reasoning traces, query performance, and error outcomes. This integration ensures observability is not just a monitoring add-on but a direct extension of reasoning transparency. Teams can identify wrapper gaps, ambiguous patterns, or performance bottlenecks by inspecting reasoning logs side-by-side with execution metrics.
Challenges and Design Implications
Building production-quality LLM database integration systems presents numerous challenges and design implications. These are not simply obstacles but architectural realities that shape how systems must be designed and maintained. Understanding them helps teams prepare for implementation complexity and proactively design mitigation strategies.
Schema Complexity and Legacy Systems
Schema complexity represents one of the most significant obstacles to successful integration. Real world databases rarely exhibit clean, well documented structures with intuitive naming conventions and clear relationships. Legacy systems often contain tables with names like “CUSTMST” or “ENROLLMT” that reflect historical character limits or development conventions rather than business meaning. The wrapper must decode these technical artifacts into comprehensible semantic descriptions.
Foreign key relationships may follow inconsistent patterns, with some connections explicit through declared constraints while others exist only as implicit conventions understood by application developers but not documented in schema metadata. Essential business logic often exists in application code rather than database constraints, requiring the wrapper to encode rules about valid status transitions, required field combinations, and calculated values that aren’t apparent from schema examination alone.
Join Path Selection and Optimization
Join path selection presents difficulties in systems with rich interconnection patterns. Multiple valid paths often exist between related entities, but only some paths respect business rules and produce meaningful results. A query about student performance might traverse from students through enrollments to classes to assignments to grades, or alternatively through students to terms to grades directly. The wrapper must encode not just the technical possibility of various paths but guidance about which approaches are semantically correct and performant.
Ambiguity Management and User Experience
Ambiguity management requires balancing user experience with accuracy requirements. Users prefer quick responses but insufficient clarification can lead to incorrect results that undermine system trust. The system must develop strategies for detecting which ambiguities are critical to resolve versus which can be handled through reasonable default assumptions.
Performance and Scalability Constraints
Performance optimization becomes particularly complex when natural language queries must be translated into efficient database operations without user involvement in optimization decisions. Users cannot be expected to understand index usage, join ordering, or result set size implications of their requests. The system must incorporate performance intelligence into the wrapper and query planning components, automatically applying optimizations that maintain result accuracy while ensuring acceptable response times.
Model Reliability and System Evolution
Model reliability presents ongoing challenges as LLM capabilities and limitations evolve. Models may produce plausible but incorrect reasoning or exhibit inconsistent behavior across similar requests. The architecture must provide sufficient validation and constraint mechanisms to detect and prevent model errors before they impact users or systems.
Maintenance overhead becomes substantial as wrapper content grows and database schemas evolve. Keeping semantic descriptions synchronized with schema changes, validating example queries, and updating policy rules as business requirements change requires systematic processes and dedicated tooling.
Implementation Examples
The following sections demonstrate specific implementation patterns that bring the architectural concepts into practice. These examples show how the abstract components translate into concrete systems that handle real-world complexity.
Catalog System Implementation
The catalog system manages entity definitions, relationships, and semantic mappings that enable LLM understanding of database structures. This implementation demonstrates how abstract wrapper concepts translate into concrete data structures:
{
"entities": {
"students": {
"fields": ["student_id", "first_name", "last_name", "email", "grade_level", "gpa"],
"synonyms": {
"first_name": ["given name", "name"],
"grade_level": ["grade", "class level"],
"gpa": ["grade point average", "academic performance"]
},
"keywords": ["student", "pupil", "learner", "enrolled"]
},
"teachers": {
"fields": ["teacher_id", "first_name", "last_name", "email", "department_id"],
"synonyms": {
"first_name": ["given name"],
"department_id": ["department", "faculty"]
},
"keywords": ["teacher", "instructor", "faculty", "staff"]
}
}
}
Example 9: Catalog system JSON structure defining entity metadata, field mappings, synonyms, and keywords for semantic understanding.
Semantic Query Builder with Business Logic
This implementation shows how natural language gets transformed into structured SQL through LLM interaction with rich schema context:
export class SemanticQueryBuilder {
constructor(private llm: LLMProvider) {}
async buildQuery(
userQuery: string,
streamReasoning?: Function,
traceId?: string
): Promise<SemanticQuery> {
const schema = SchemaManager.getSchema();
const prompt = this.buildSemanticPrompt(userQuery, schema);
const response = await this.llm.rawCompletion(prompt);
const semanticQuery = JSON.parse(this.extractJSON(response));
streamReasoning?.(traceId, 'semantic_query_built', {
message: `Query built: ${semanticQuery.reasoning}`,
sql: semanticQuery.sql,
confidence: semanticQuery.confidence
});
return semanticQuery;
}
private buildSemanticPrompt(userQuery: string, schema: any): string {
return `You are an expert SQL developer. Convert this natural language query to SQL.
AVAILABLE DATABASE SCHEMA:
${JSON.stringify(schema, null, 2)}
EXAMPLES:
1. "How many students are in grade 9?"
{"sql": "SELECT COUNT(*) as total_students FROM students WHERE grade_level = 9 AND status = 'Active'",
"params": [],
"columns": ["total_students"],
"reasoning": "User wants count of active students in grade 9",
"confidence": 0.95}
User Query: "${userQuery}"
Respond with JSON only:
{
"sql": "SELECT ... FROM ... WHERE ...",
"params": [],
"columns": ["col1", "col2"],
"reasoning": "User wants to [explanation]",
"confidence": 0.95
}`;
}
}
Example 10: Semantic Query Builder implementation showing how natural language gets transformed into structured SQL through LLM interaction with rich schema context.
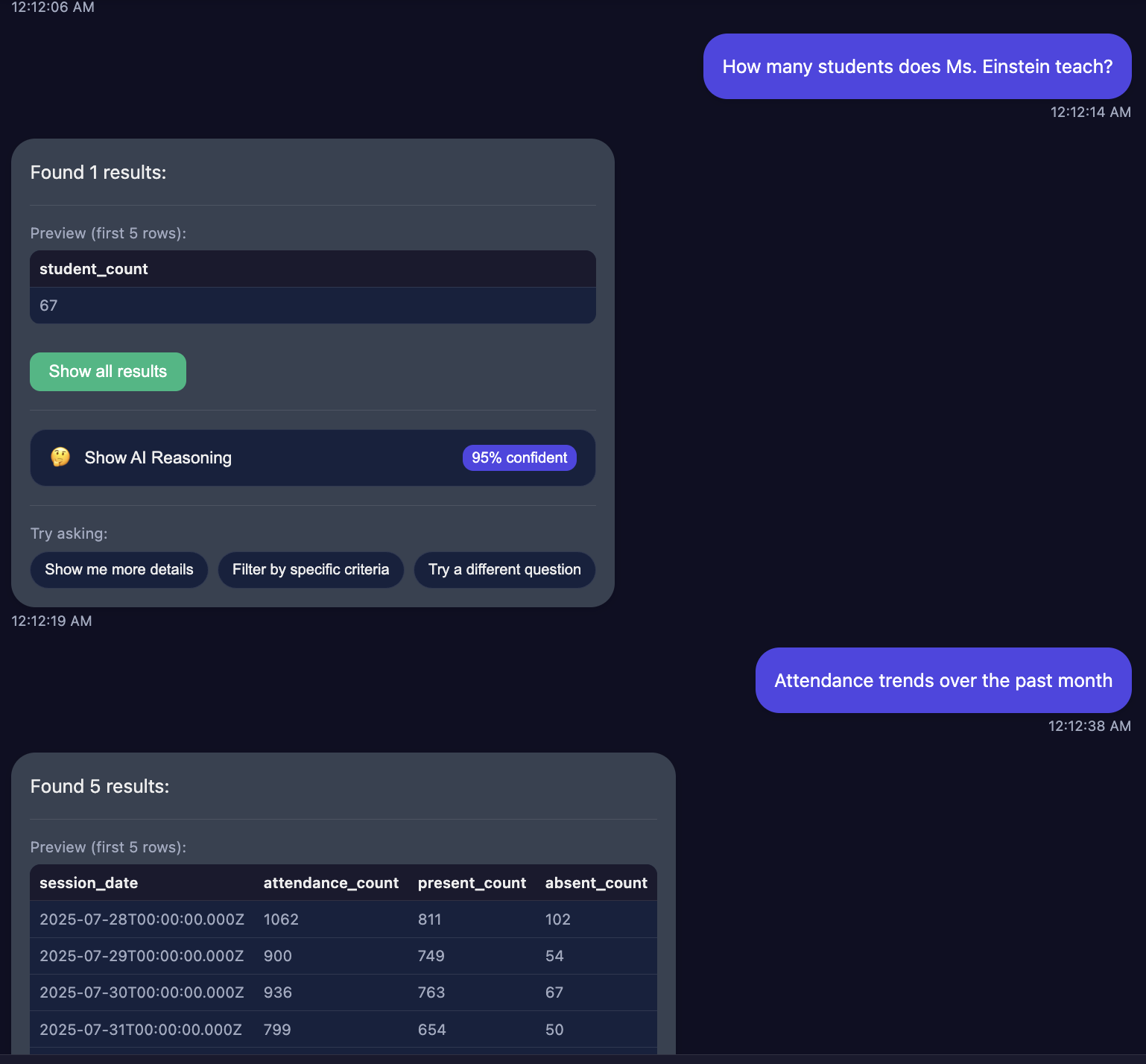
Figure 6: Live demonstration of the Semantic Query Builder processing natural language input and generating SQL with reasoning transparency and confidence scoring.
Progressive Reasoning Chain Architecture
This implementation shows how to build step-by-step reasoning systems that make decision processes transparent and enable debugging of complex query processing:
const reasoningPrompt = `Break down this query into sequential reasoning steps:
Query: "${userQuery}"
Previous Steps: ${JSON.stringify(completedSteps)}
For the next step, determine:
1. What specific question needs answering?
2. What information from previous steps is needed?
3. What's the confidence level?
Respond with JSON:
{
"step_type": "understand|plan|execute|analyze",
"reasoning": "what this step accomplishes",
"dependencies": ["step_1", "step_2"],
"confidence": 0.8
}`;
class ProgressiveReasoningChain {
async executeChain(userQuery) {
const steps = [];
// Step 1: Understand
steps.push(await this.reason("understand", userQuery, []));
// Step 2: Plan
steps.push(await this.reason("plan", userQuery, [steps[0]]));
// Step 3: Execute (or Clarify if needed)
if (steps[1].needsClarification) {
return await this.reason("clarify", userQuery, steps);
}
steps.push(await this.reason("execute", userQuery, steps));
// Step 4: Analyze (if complex)
if (steps[1].isComplex) {
steps.push(await this.reason("analyze", userQuery, steps));
}
return steps[steps.length - 1].output;
}
async reason(stepType, query, previousSteps) {
const prompt = buildReasoningPrompt(stepType, query, previousSteps);
const response = await llm.complete(prompt);
streamToUser(`${stepType}: ${response.reasoning}`);
return response;
}
}
Example 11: Progressive Reasoning Chain implementation demonstrating step-by-step reasoning systems that make decision processes transparent and enable debugging of complex query processing.
Hierarchical Task Breakdown System
This implementation demonstrates workflow orchestration that decomposes complex multi-step operations into manageable, executable tasks with proper dependency tracking:
export interface PlanTask {
id: string;
intent: 'read' | 'analyze' | 'clarify' | 'format' | 'filter' | 'transform';
goal: string;
dependencies: string[];
estimatedComplexity: 'low' | 'medium' | 'high';
requiredEntities: string[];
potentialAmbiguities: string[];
status: 'pending' | 'in_progress' | 'completed' | 'failed';
}
export class QueryPlanner {
constructor(private llm: LLMProvider) {}
async createPlan(
userQuery: string,
conversationContext: any,
streamReasoning?: Function,
traceId?: string
): Promise<PlanSpec> {
const schema = SchemaManager.getSchema();
const prompt = this.buildPlanningPrompt(userQuery, schema, conversationContext);
const response = await this.llm.rawCompletion(prompt);
const rawPlan = JSON.parse(this.extractJSON(response));
const plan: PlanSpec = {
id: `plan_${Date.now()}`,
originalQuery: userQuery,
tasks: rawPlan.tasks.map((task: any, index: number) => ({
...task,
id: `task_${index + 1}`,
status: 'pending' as const
})),
executionOrder: this.calculateExecutionOrder(rawPlan.tasks),
requiresClarification: rawPlan.requiresClarification || false,
reasoning: rawPlan.reasoning,
confidence: rawPlan.confidence || 0.8
};
return plan;
}
private buildPlanningPrompt(userQuery: string, schema: any, context: any): string {
return `You are an expert query planner for a database system.
DATABASE SCHEMA:
${JSON.stringify(schema, null, 2)}
USER QUERY: "${userQuery}"
Break down complex queries into logical tasks. Consider:
TASK INTENTS:
- "read": Database queries to retrieve data
- "analyze": Correlate/combine multiple data sources
- "clarify": Need user input for ambiguous terms
- "filter": Apply specific criteria to existing data
EXAMPLE - Complex Query:
Query: "Students struggling academically who need intervention"
{
"tasks": [
{
"intent": "clarify",
"goal": "Define academic struggle criteria",
"dependencies": [],
"estimatedComplexity": "low",
"requiredEntities": ["students", "grades"],
"potentialAmbiguities": ["What GPA defines struggling?"]
},
{
"intent": "read",
"goal": "Find students meeting struggle criteria",
"dependencies": [],
"estimatedComplexity": "medium",
"requiredEntities": ["students", "grades", "enrollments"],
"potentialAmbiguities": []
}
],
"requiresClarification": true,
"reasoning": "Complex analysis requiring criteria clarification",
"confidence": 0.75
}
Respond with JSON only.`;
}
}
Example 12: Hierarchical Task Breakdown System showing workflow orchestration that decomposes complex multi-step operations into manageable, executable tasks with proper dependency tracking.
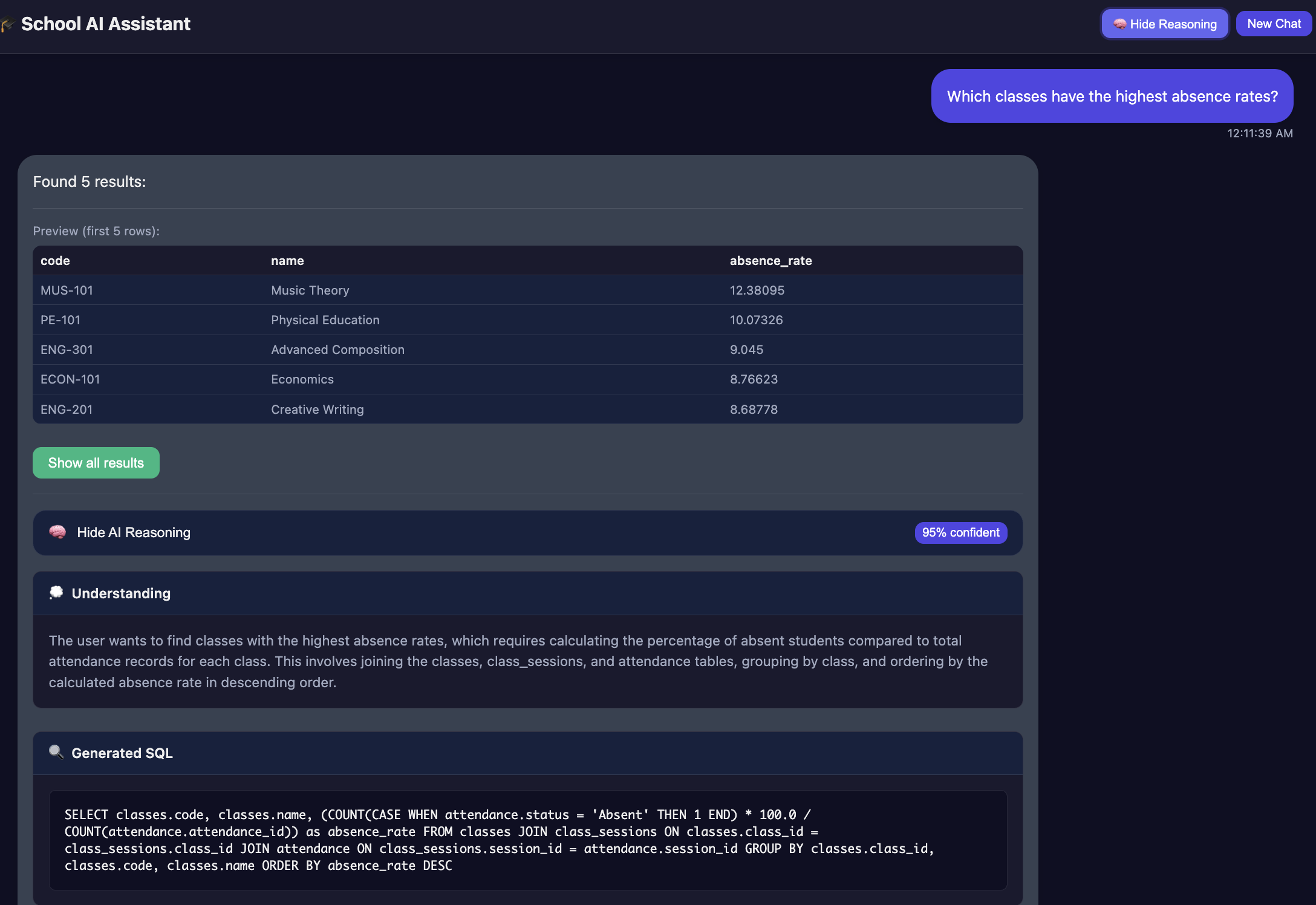
Figure 7: Complete system integration proof of concept showing end-to-end workflow from natural language input through schema understanding, operation planning, and execution with comprehensive audit trails.
Limitations and Failure Modes
While this architecture provides a robust foundation for LLM-database integration, it introduces complexity that may not be justified for all systems and carries inherent risks that teams must carefully consider.
When This Architecture Is Overkill
Organizations with simple, well-documented schemas and predictable query patterns may find the wrapper development overhead exceeds the benefits. A straightforward e-commerce platform with basic product catalogs and order tables might achieve better results with simpler validation layers and direct SQL generation. The semantic wrapper approach becomes cost-prohibitive when wrapper maintenance requires more engineering time than building traditional query interfaces.
Startups and small teams face particular challenges with this architecture. The upfront investment in wrapper development, domain expertise requirements, and ongoing maintenance can consume resources better allocated to core product features. Systems serving fewer than 100 concurrent users rarely justify the architectural complexity required for comprehensive semantic translation.
Critical Failure Scenarios
Wrapper Schema Drift: The wrapper can become inconsistent with actual database schemas during rapid development cycles, leading to systematic query failures that are difficult to diagnose. When wrapper definitions lag behind schema changes, the system generates valid-looking but failing operations that erode user trust.
Semantic Ambiguity Accumulation: As domain vocabulary grows, semantic mappings can develop conflicts where the same terms map to multiple valid interpretations. Without careful curation, the wrapper becomes internally inconsistent, causing unpredictable query generation behavior.
Model Degradation Under Load: LLM performance degrades with excessive context, but comprehensive wrappers naturally grow large. Systems experience reliability issues when wrapper context exceeds model processing capabilities, leading to truncated reasoning or hallucinated responses.
Cascade Validation Failures: Complex validation chains create brittle systems where minor policy changes can break seemingly unrelated operations. Dependencies between validation rules, business logic, and security policies become difficult to track and maintain.
Performance and Scalability Limitations
The multi-stage reasoning pipeline introduces latency that may be unacceptable for real-time applications. Systems requiring sub-second response times struggle with the semantic understanding, planning, and validation overhead. High-throughput scenarios reveal bottlenecks in wrapper consultation and reasoning chain generation.
Wrapper complexity grows quadratically with schema size, making this approach impractical for systems with hundreds of tables or complex many-to-many relationships. The join path explosion problem becomes computationally expensive as the system attempts to evaluate all possible semantic routes between entities.
Takeaways
Building reliable LLM database integration requires recognizing this as a systems architecture challenge rather than a prompt engineering problem. The intelligence resides not in the language models but in the structured frameworks that guide their operation and constrain their behavior within safe boundaries.
Architectural Foundations
Wrapper First: The Schema Wrapper emerges as the most critical component. Teams should devote significant time and care to building rich semantic descriptions, canonical join paths, policy rules, and example libraries, as these form the foundation on which everything else rests. This semantic layer must evolve beyond simple schema documentation to become a comprehensive domain knowledge system that encodes not just what exists but how it should be interpreted and used.
Reasoning Transparency: Users and developers must see how results were derived. Exposing reasoning traces builds trust through explainability and provides debugging capabilities when systems produce unexpected results. This transparency becomes particularly crucial for sensitive operations like data modifications and workflow orchestrations where users need confidence that business rules are respected.
User Experience Design
Collaborative Clarification: Traditional systems fail on ambiguous requests with generic error messages. Mature architectures transform ambiguity into collaborative opportunities, generating specific questions that educate users about domain concepts while resolving uncertainty. This creates positive feedback loops where users learn to formulate more precise requests.
Partial Context Management: Large language models perform poorly when overwhelmed with excessive context. The solution lies in ground slicing techniques that provide models with precisely the schema elements, policy rules, and examples relevant to each specific query, enabling systems to scale to enterprise schemas while maintaining reasoning quality.
Production Requirements
Safety by Design: Production incidents caused by unsafe queries or policy violations represent systemic architecture failures. Safety mechanisms must be integrated from initial design through multiple validation layers: schema consistency checks, access control verification, business rule enforcement, and resource consumption limits.
Beyond Simple Queries: Real world usage extends far beyond SELECT statements. Data modifications, external API integrations, and multi step workflows must be treated as first class intents with the same safety and reasoning guarantees as simple queries, complete with dedicated validation pathways and rollback mechanisms.
Observability for Evolution: Comprehensive telemetry tied to reasoning traces enables continuous system improvement. Teams can identify wrapper deficiencies, recognize user confusion patterns, and detect emerging failure modes by analyzing reasoning logs alongside execution metrics. Without this foundation, systems drift as schemas evolve and user needs change.
Implementation Reality
Success with this architecture requires sustained engineering investment, with wrapper development representing the largest portion of initial construction effort. Organizations must balance this architectural complexity against alternatives like brittle rule based systems or unsafe direct model access to production data.
These patterns generalize across domains from education to healthcare to finance and scale from prototypes to production systems serving thousands of users. The approach transforms databases from rigid technical repositories into conversational partners that maintain business rules, security boundaries, and transparent reasoning about their decisions while democratizing data access across complex organizational domains.