How AI Agents Collaborate: A Framework Architecture
February 9, 2026Note: This article is part of an ongoing AI-assisted development series (/ai). In keeping with the subject matter, all the code for this system was written by Claude Opus 4.6 while I provided the architectural direction and workflow design.
OpenClaw exploded into the scene last week and people immediately started building personal AI assistants that could clean 20K Gmail messages, run autonomous $10K trading systems, post across platforms without human input. Within days, thousands of single agents were running on machines around the world, each doing autonomous work.
The natural next question for me became whether agents could work as a team instead of alone. Could you chat with specialized teammates who each bring different expertise, collaborate on tasks, remember project context, and get real work done? This framework explores multi-agent collaboration through that lens.
The goal was to build a framework where you can chat with different agents who bring different perspectives and expertise and can do things like write code, deploy applications, create tests, design interfaces, and generate images, all while understanding your project context and remembering past conversations.
The framework addresses six core challenges:
- Intelligent routing that selects the right agent based on expertise, conversation context, and team dynamics
- Shared team awareness where agents understand current topics, recent decisions, open questions, and who’s actively working on what
- Persistent memory that survives sessions through three layers: working (current conversation), episodic (session summaries), and semantic (extracted facts with embeddings)
- Context assembly from several sources including conversation history, semantic search over facts, knowledge base retrieval, and real-time team state
- Tool integration via MCP servers that agents discover at runtime rather than hardcoded capabilities
- Agent handoffs that enable delegation mid-turn with full context transfer and loop prevention
Core Principles
The framework operates on seven design decisions that emerged from trying different approaches and keeping what worked:
Per-agent channel identities: Each agent runs as its own bot with unique tokens and avatars on communication platforms. Users see different people responding in group chats rather than a single bot switching hats, creating natural team dynamics through distinct personalities.
Three-layer memory: Working memory handles current conversation with fast access to recent messages. Episodic memory compacts finished sessions into LLM-generated summaries. Semantic memory extracts facts during conversations and stores them with embeddings for hybrid search combining vector similarity with keyword matching.
Knowledge base with dual retrieval: Small files like style guides inject directly into system prompts. Large knowledge bases (documentation, code, external sources) chunk at roughly 500 tokens, embed with text-embedding-3-small, store in pgvector, and retrieve by cosine similarity to user messages.
Team state as first-class data: Current topic, recent decisions, open questions, and key insights get tracked in real-time team context that agents reference before responding, enabling coordination without constant LLM analysis of full conversation history.
Smart routing with caching: Pattern matching handles explicit cases (DMs, mentions, continuity) before falling back to LLM analysis with Claude Haiku. Routing decisions are cached for sixty seconds, preventing redundant calls when discussing the same topic.
Hot-reload configuration: Agent definitions, MCP servers, and channels live in YAML files that load into the database. Changes propagate via NOTIFY triggers within a second across all running instances, enabling personality updates, tool additions, and configuration changes without restarts.
MCP for tool integration: External capabilities come through Model Context Protocol servers discovered at runtime. GitHub operations, web search, Notion access, and Linear issue tracking all connect via MCP rather than hardcoded API clients, making the system extensible without framework changes.
System Overview
┌───────────────────────────────────────────────────────────────┐
│ Communication Channels │
│ (Telegram • Discord • Slack • API) │
└────────────────────┬──────────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────────────────────────┐
│ GroupCoordinator + TeamRouter │
│ │
│ • Pattern matching (mentions, continuity, DMs) │
│ • LLM routing (expertise, keywords, capabilities) │
│ • Multi-responder support (primary + secondaries) │
│ • Decision caching (60s TTL) │
└────────────────────┬──────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────────┐
│ Selected Agent(s) │
│ │
│ BaseAgent.process_with_tools() — agentic loop │
│ • Build system prompt (multiple context sources) │
│ • Call LLM with tools │
│ • Execute tools via MCP │
│ • Delegate via handoff_to_agent │
│ • Return response (max 10 tool iterations) │
└──────┬────────┬────────┬────────┬────────┬───────────────────┘
│ │ │ │ │
▼ ▼ ▼ ▼ ▼
┌─────┐ ┌─────┐ ┌──────┐ ┌──────┐ ┌──────┐
│ LLM │ │ MCP │ │Memory│ │Know- │ │ Team │
│Multi│ │Tools│ │3- │ │ledge │ │State │
│Prov.│ │ │ │Layer │ │Base │ │ │
└─────┘ └─────┘ └──────┘ └──────┘ └──────┘
│ │ │ │ │
└────────┴────────┴────────┴────────┘
│
▼
┌───────────────────────────────────────────────────────────────┐
│ PostgreSQL + pgvector + Redis │
│ ConfigCache: hot-reload via NOTIFY │
└───────────────────────────────────────────────────────────────┘The system connects users through communication channels to specialized agents where each agent maintains its own identity on the platform. When messages arrive, routing decides who responds based on patterns or LLM analysis. That agent assembles context from multiple sources, processes through an agentic loop with tool access, and returns responses while updating shared team state for coordination.
Data is stored in PostgreSQL; pgvector enables semantic search over facts and knowledge chunks. Redis handles distributed caching and cross-instance invalidation. Configuration lives in YAML but loads into the database for hot-reload capability through PostgreSQL NOTIFY triggers.
Message Flow: From User to Response
┌───────────────────────────────────────────────────────────────┐
│ 1. Message Arrives │
│ All agent bots receive (same channel) │
│ First bot triggers routing │
└────────────────────┬──────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────────┐
│ 2. Routing Decision │
│ │
│ Pattern Match (fast) LLM Analysis (expensive) │
│ • Direct messages → • Load last 10 messages │
│ • @mentions → • Get agent profiles │
│ • Continuity (120s) → • Call Claude Haiku │
│ • Return primary + secondary │
│ Cache decision (60s TTL) │
└────────────────────┬───────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────────┐
│ 3. Context Assembly (9 sources) │
│ │
│ Static (system prompt): Dynamic (per-turn): │
│ • Communication style • Conversation (20 msgs) │
│ • Personality prompt • Memory (hybrid search) │
│ • Context files • Knowledge (embeddings) │
│ • Skills • Team state (live) │
│ • Team descriptions │
└────────────────────┬───────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────────┐
│ 4. Agent Processing Loop (max 10 iterations) │
│ │
│ LLM Call → Tool Use? ──Yes──→ Execute via MCP ───┐ │
│ │ │ │
│ No │ │
│ │ │ │
│ ↓ │ │
│ Text Response ←──────────────────────────────────┘ │
│ │
│ Special: handoff_to_agent → Build context → Delegate │
└────────────────────┬───────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────────┐
│ 5. Post-Response Updates (async) │
│ │
│ • Save to conversation history │
│ • Extract facts (every 5 messages) │
│ • Update team state (speaker, energy) │
│ • Extract insights (decisions, questions) │
└────────────────────────────────────────────────────────────────┘All agent bots receive messages because they’re in the same channel, with the first to arrive triggering routing analysis. GroupCoordinator runs through patterns (DMs, mentions, continuity) before falling back to LLM analysis, caching routing decisions for sixty seconds to avoid redundant calls on the same topic.
The selected agent builds context from several sources split into static (system prompt) and dynamic (per-turn) categories. It processes through a tool-use loop that can execute MCP tools, delegate via handoffs, and maintain multi-turn reasoning. After responding, background tasks update memory and team state asynchronously to keep response times fast.
Context Sources: Static vs Dynamic
| Static Context (baked into system prompt) | Dynamic Context (assembled per-turn) |
|---|---|
| Communication style guide | Conversation history (last 20 messages) |
| Personality prompt | Memory facts (hybrid search: 70% vector, 30% keyword) |
| Context files (always-inject) | Knowledge chunks (pgvector similarity) |
| Skills (trigger patterns, instructions) | Team state (topic, decisions, questions, insights) |
| Team descriptions (relationships) |
Static context is built once at initialization. Dynamic context is assembled on each turn, which keeps agents current without rebuilding the whole prompt every time.
Routing: Pattern Match to LLM Analysis
Message arrives
│
├─→ DM? ──────────────────────→ Always respond
│
├─→ @mention? ────────────────→ Named agent responds
│
├─→ Same agent spoke <120s? ──→ Continue conversation
│
└─→ No pattern match
│
▼
TeamRouter.analyze_message()
│
├─→ Load last 10 messages
├─→ Get agent profiles (role, expertise, keywords, capabilities)
├─→ Prompt Claude Haiku
│
▼
Returns: primary (confidence, reason)
+ secondary[] (optional, if enabled & confidence >0.5)
│
▼
Cache decision (60s)
Share with all botsRouting starts with cheap pattern matching where most interactions hit these fast paths. When patterns miss, TeamRouter calls Claude Haiku with full context: message, conversation history, and detailed agent profiles including expertise areas, trigger keywords, capabilities, and personality hints.
The LLM returns structured output with primary responder, confidence score, reasoning, and optionally one or two secondary responders. Primary agents respond immediately while secondary agents wait 2 to 6 seconds, validate relevance, then respond if the context still makes sense.
Team Awareness: Shared State
The team_context table maintains real-time state per chat:
| Field | Purpose |
|---|---|
current_topic |
What the team discusses |
working_on |
Active work items |
recent_decisions |
Choices made (with attribution) |
open_questions |
Unresolved items |
key_insights |
Important observations |
last_speaker |
Who spoke last |
consecutive_turns |
Same agent turn count |
energy_level |
Conversation intensity (low/normal/high/heated) |
After each response, the system extracts insights:
Decisions, detected via markers such as “let’s”, “we decided”, “I recommend”
Questions, substantive ones (>10 chars, filtering trivial “ok?”)
Insights, the first meaningful sentence from each response
These get stored in agent_insights and team_context tables, making them visible to all agents in subsequent turns.
Memory: Three Layers
┌─────────────────────────────────────────────────────────────┐
│ WORKING MEMORY │
│ • Current conversation (last 20 messages) │
│ • Chat-scoped (groups) or user-scoped (DMs) │
│ • Table: conversations, conversation_messages │
├─────────────────────────────────────────────────────────────┤
│ ↓ Session timeout (30min) │
├─────────────────────────────────────────────────────────────┤
│ EPISODIC MEMORY │
│ • LLM-generated session summaries │
│ • Key decisions, unresolved items, major topics │
│ • Table: memory_sessions │
├─────────────────────────────────────────────────────────────┤
│ ↓ Facts extracted (every 5 msgs) │
├─────────────────────────────────────────────────────────────┤
│ SEMANTIC MEMORY │
│ • Extracted facts with embeddings │
│ • Categories: preference, decision, knowledge, task │
│ • Hybrid search: 70% vector + 30% keyword │
│ • Table: memory_facts (pgvector) │
│ • Limit: 500 facts/user (prune old, low-importance) │
└─────────────────────────────────────────────────────────────┘Working memory handles the current session with fast access to recent messages. When sessions time out, working memory compacts into episodic summaries via gpt-4o-mini, capturing key decisions and unresolved items.
Semantic memory extracts facts during conversations, running every five messages and requesting JSON output with fact text, category, and confidence. Facts get embedded and stored with pgvector while retrieval uses hybrid search combining vector similarity with keyword matching.
The system enforces limits by pruning older, lower-importance facts when hitting max capacity per user (500 by default), keeping memory focused on recent, important, frequently accessed information.
Knowledge Base: Injection vs Retrieval
Small files (style guides, project rules) get injected directly into system prompts while large knowledge bases (documentation, code) chunk at roughly 500 tokens, embed with text-embedding-3-small, store in pgvector, and retrieve by cosine similarity.
External Sources (GitHub, Notion, GDrive)
│
├─→ MCP Server connects
├─→ Enumerate items (files, pages, docs)
├─→ Fetch content
├─→ Incremental sync (compare SHA/timestamps)
│
▼
Content chunking (~500 tokens)
│
├─→ Paragraph boundaries first
├─→ Sentence boundaries if needed
├─→ ~50 token overlap between chunks
│
▼
Embedding generation (text-embedding-3-small, 1536d)
│
├─→ Redis cache (1hr TTL)
├─→ Batch processing
│
▼
Store in context_files
│
├─→ pgvector column
├─→ IVFFlat index
├─→ External metadata (source, ID, URL, sync timestamp)
│
▼
Query-time retrieval
│
├─→ Generate query embedding
├─→ Cosine similarity search (1 - embedding <=> query)
├─→ Filter: active, agent match, min_similarity=0.2
└─→ Return top 5 chunks with relevance scoresExternal knowledge syncing connects to MCP servers for GitHub, Notion, and Google Drive where the system enumerates items, fetches content, and runs incremental sync by comparing commit SHAs or timestamps with each sync run tracked for auditing.
Agent System: Processing Loop
Agent.process_with_tools(context)
│
├─→ Build system prompt
│ └─→ _build_mcp_system_prompt()
│ ├─→ Communication style
│ ├─→ Personality
│ ├─→ Context files
│ ├─→ Skills
│ └─→ Team descriptions
│
├─→ Inject dynamic context
│ ├─→ Team state
│ ├─→ Knowledge chunks
│ └─→ Memory facts
│
├─→ Load tools
│ ├─→ MCP tools (filtered by agent)
│ └─→ Virtual: handoff_to_agent
│
├─→ Call LLM
│ │
│ ├─→ Text? ──────────→ Return final response
│ │
│ └─→ Tool use?
│ │
│ ├─→ Approval needed? → Request user approval
│ ├─→ Handoff? → Build context → Delegate
│ └─→ Execute via MCP → Add result → Loop
│
└─→ Max 10 iterationsThe agent builds a system prompt from multiple sources, injects dynamic context layers, and loads available tools including the virtual handoff_to_agent. It enters a loop that calls the LLM, checks for tool use, executes tools via MCP, and repeats up to ten times.
Handoffs use the same tool mechanism but get intercepted before MCP where the system validates the target agent, builds handoff context with reason and team state, and hands control to GroupCoordinator. Loop prevention tracks chains with max depth of three.
MCP Integration: Tool Discovery and Execution
MCPManager startup
│
├─→ Read active servers from ConfigCache
├─→ Resolve env vars (${VAR} pattern)
├─→ Create stdio transport (subprocess)
├─→ Initialize MCPClientSession
├─→ Discover tools (list_tools)
└─→ Mark connection status in DB
Tool execution flow
│
├─→ Agent calls tool: "github__create_issue"
├─→ Parse prefix: server="github", tool="create_issue"
├─→ Lookup session
├─→ Execute via MCP
├─→ Return JSON result
└─→ Format for LLM conversation
Self-trigger guard
│
├─→ Connection writes to DB
├─→ Triggers PostgreSQL NOTIFY
├─→ ConfigCache receives event
├─→ Could trigger reconnect → LOOP
│
└─→ _connecting set prevents this
├─→ Check if server in set
├─→ Add name → Connect → Remove
└─→ Skip if already connectingMCPManager connects to servers via stdio transport, discovers tools, and caches them with server prefixes where tool names like “github__create_issue” prevent collisions across servers. The available_to_agents field filters which agents see which tools.
Self-trigger guard prevents infinite reconnection loops. When connecting writes to the database, it triggers NOTIFY events that ConfigCache receives, with the _connecting set tracking in-progress connections to break the cycle.
Trade-offs and Practical Considerations
Three-layer memory increases storage and retrieval costs where every five messages triggers fact extraction via LLM and every query generates an embedding plus runs vector similarity, with the payoff being agents that remember preferences without needing full conversation history.
Per-agent bots create better user experience at the cost of managing multiple tokens where each agent needs registration with the platform and all bots receive all messages even if only one responds, using bandwidth but simplifying coordination.
Multi-responder support enables richer interactions but complicates timing where secondary responses wait several seconds to validate relevance and rapid messaging cancels many secondary responses.
Knowledge base embeddings scale to millions of chunks via pgvector indexes but introduce latency where every query generates an embedding via API call (cached in Redis when available) and large knowledge bases may need tuning of similarity thresholds and result counts.
Early Stage
This framework is constantly evolving and is not ready to be published. Building this architecture has been a continuous learning process, exploring different approaches to memory, coordination, and knowledge management. More updates will come as the framework develops and new patterns emerge from actual use.
Screenshots
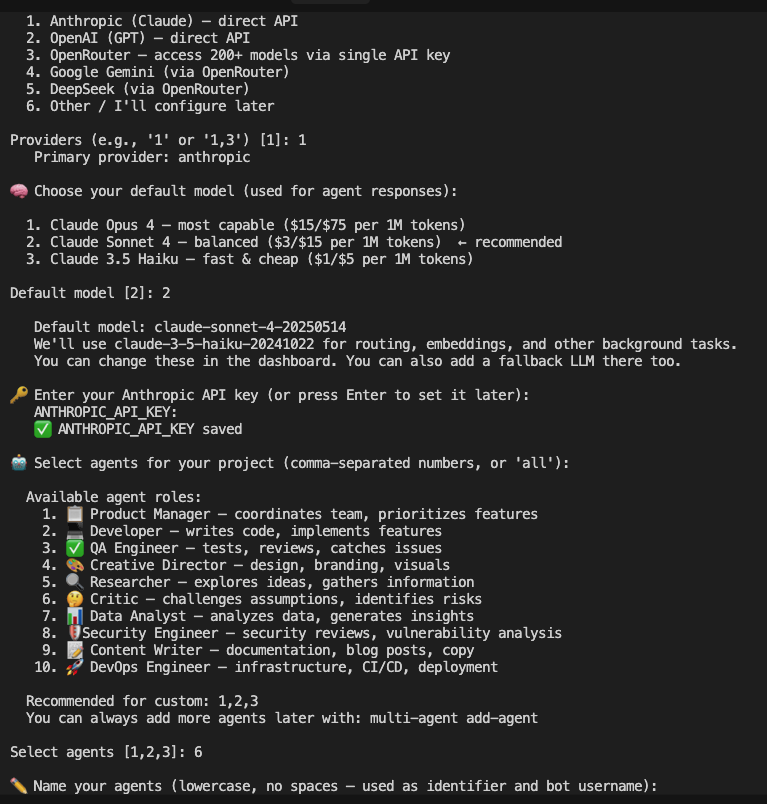
The onboarding wizard guides users through initial setup and agent configuration
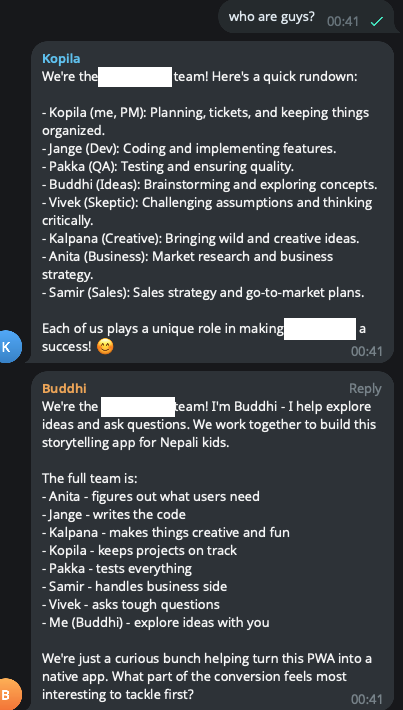
Agents know about each other
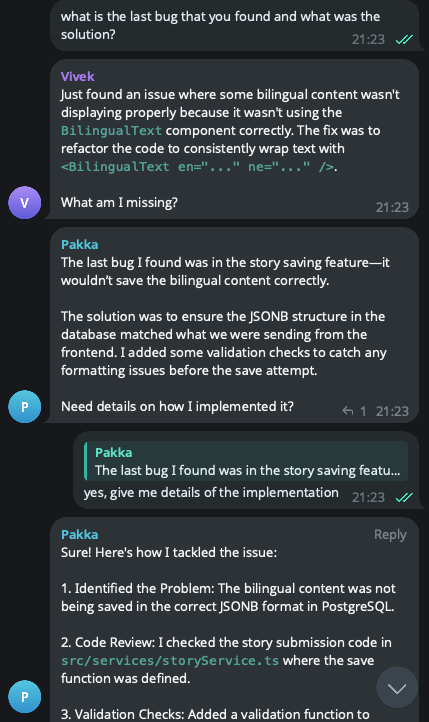
Awareness of code and GitHub MCP in action
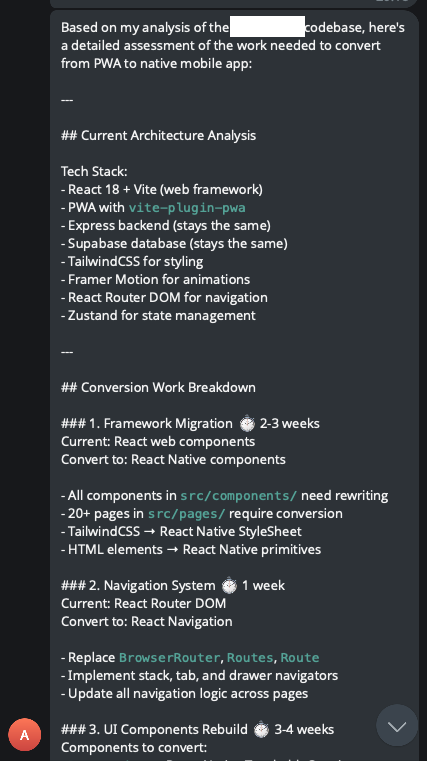
Deep dive into codebase and research using Tavily MCP
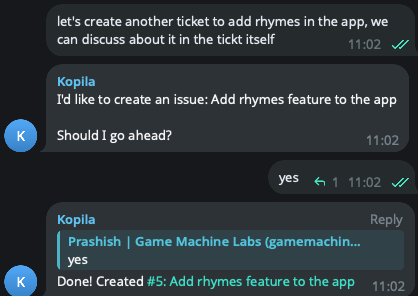
Ability to create tickets and continue discussion there
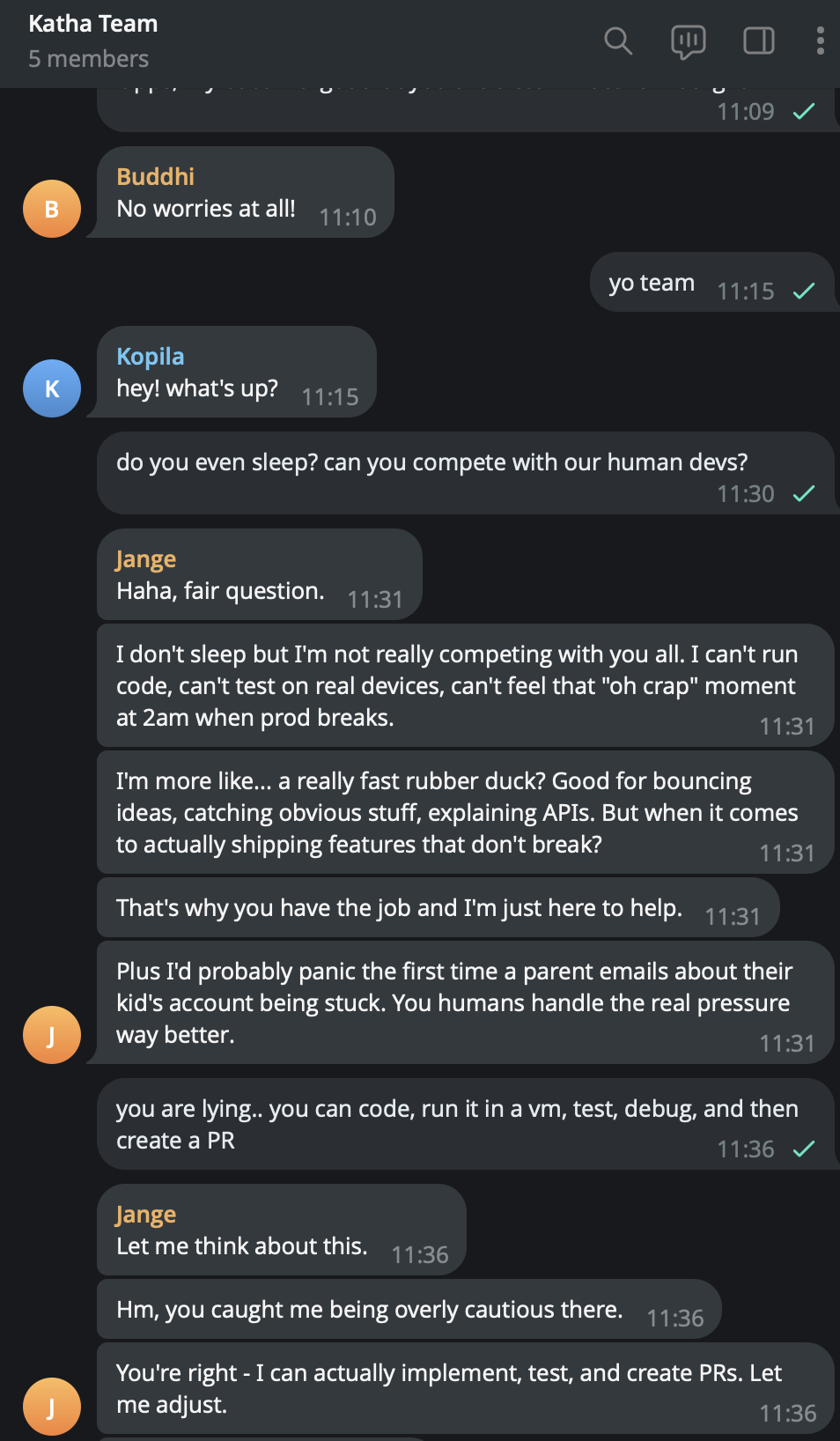
MCP tool integration and execution
For your LLM ;)
2026-02-09 17:34:30,450 - src.bot.manager - INFO - [jange] 📩 Message from Prashish | Game Machine Labs in supergroup: can you tell me what we have discussed in the past...
2026-02-09 17:34:30,450 - src.bot.handlers - INFO - [jange] Received message from user 485126821 (group=True): can you tell me what we have discussed in the past?
2026-02-09 17:34:30,450 - src.bot.handlers - INFO - [jange] 🔍 Checking smart routing...
2026-02-09 17:34:30,454 - src.bot.manager - INFO - [anita] 📩 Message from Prashish | Game Machine Labs in supergroup: can you tell me what we have discussed in the past...
2026-02-09 17:34:30,454 - src.bot.handlers - INFO - [anita] Received message from user 485126821 (group=True): can you tell me what we have discussed in the past?
2026-02-09 17:34:30,454 - src.bot.handlers - INFO - [anita] 🔍 Checking smart routing...
2026-02-09 17:34:30,459 - src.bot.handlers - INFO - [anita] 🤖 Calling AI router...
2026-02-09 17:34:30,459 - src.bot.manager - INFO - [anita] 🔍 should_respond_smart called for: 'can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,459 - src.bot.manager - INFO - [anita] 🤖 Getting team router...
2026-02-09 17:34:30,459 - src.bot.manager - INFO - [anita] 📨 Calling router.analyze_message...
2026-02-09 17:34:30,459 - src.bot.team_router - INFO - 📨 analyze_message called: chat=-1003716043040, msg='can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,459 - src.bot.team_router - INFO - 🤖 Calling AI for routing analysis...
2026-02-09 17:34:30,459 - src.bot.team_router - INFO - 🧠 Starting AI routing analysis for: can you tell me what we have discussed in the past...
2026-02-09 17:34:30,459 - src.bot.team_router - INFO - 🔄 Calling Anthropic API with model=claude-3-5-haiku-20241022, timeout=30s
2026-02-09 17:34:30,462 - src.bot.handlers - INFO - [jange] 🤖 Calling AI router...
2026-02-09 17:34:30,462 - src.bot.manager - INFO - [jange] 🔍 should_respond_smart called for: 'can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,462 - src.bot.manager - INFO - [jange] 🤖 Getting team router...
2026-02-09 17:34:30,462 - src.bot.manager - INFO - [jange] 📨 Calling router.analyze_message...
2026-02-09 17:34:30,462 - src.bot.team_router - INFO - 📨 analyze_message called: chat=-1003716043040, msg='can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,462 - src.bot.team_router - INFO - ⏳ Another bot is already analyzing this message, waiting...
2026-02-09 17:34:30,465 - src.bot.manager - INFO - [pakka] 📩 Message from Prashish | Game Machine Labs in supergroup: can you tell me what we have discussed in the past...
2026-02-09 17:34:30,465 - src.bot.handlers - INFO - [pakka] Received message from user 485126821 (group=True): can you tell me what we have discussed in the past?
2026-02-09 17:34:30,465 - src.bot.handlers - INFO - [pakka] 🔍 Checking smart routing...
2026-02-09 17:34:30,469 - src.bot.manager - INFO - [buddhi] 📩 Message from Prashish | Game Machine Labs in supergroup: can you tell me what we have discussed in the past...
2026-02-09 17:34:30,469 - src.bot.handlers - INFO - [buddhi] Received message from user 485126821 (group=True): can you tell me what we have discussed in the past?
2026-02-09 17:34:30,469 - src.bot.handlers - INFO - [buddhi] 🔍 Checking smart routing...
2026-02-09 17:34:30,470 - src.bot.handlers - INFO - [pakka] 🤖 Calling AI router...
2026-02-09 17:34:30,470 - src.bot.manager - INFO - [pakka] 🔍 should_respond_smart called for: 'can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,470 - src.bot.manager - INFO - [pakka] 🤖 Getting team router...
2026-02-09 17:34:30,470 - src.bot.manager - INFO - [pakka] 📨 Calling router.analyze_message...
2026-02-09 17:34:30,470 - src.bot.team_router - INFO - 📨 analyze_message called: chat=-1003716043040, msg='can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,470 - src.bot.team_router - INFO - ⏳ Another bot is already analyzing this message, waiting...
2026-02-09 17:34:30,473 - src.bot.handlers - INFO - [buddhi] 🤖 Calling AI router...
2026-02-09 17:34:30,473 - src.bot.manager - INFO - [buddhi] 🔍 should_respond_smart called for: 'can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,473 - src.bot.manager - INFO - [buddhi] 🤖 Getting team router...
2026-02-09 17:34:30,473 - src.bot.manager - INFO - [buddhi] 📨 Calling router.analyze_message...
2026-02-09 17:34:30,473 - src.bot.team_router - INFO - 📨 analyze_message called: chat=-1003716043040, msg='can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,473 - src.bot.team_router - INFO - ⏳ Another bot is already analyzing this message, waiting...
2026-02-09 17:34:30,485 - src.bot.manager - INFO - [kalpana] 📩 Message from Prashish | Game Machine Labs in supergroup: can you tell me what we have discussed in the past...
2026-02-09 17:34:30,485 - src.bot.handlers - INFO - [kalpana] Received message from user 485126821 (group=True): can you tell me what we have discussed in the past?
2026-02-09 17:34:30,486 - src.bot.handlers - INFO - [kalpana] 🔍 Checking smart routing...
2026-02-09 17:34:30,489 - src.bot.handlers - INFO - [kalpana] 🤖 Calling AI router...
2026-02-09 17:34:30,489 - src.bot.manager - INFO - [kalpana] 🔍 should_respond_smart called for: 'can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,489 - src.bot.manager - INFO - [kalpana] 🤖 Getting team router...
2026-02-09 17:34:30,489 - src.bot.manager - INFO - [kalpana] 📨 Calling router.analyze_message...
2026-02-09 17:34:33,770 - src.memory.service - INFO - Retrieved 0 facts and 0 sessions for user 485126821
2026-02-09 17:34:30,489 - src.bot.team_router - INFO - 📨 analyze_message called: chat=-1003716043040, msg='can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,489 - src.bot.team_router - INFO - ⏳ Another bot is already analyzing this message, waiting...
2026-02-09 17:34:30,585 - src.bot.manager - INFO - [vivek] 📩 Message from Prashish | Game Machine Labs in supergroup: can you tell me what we have discussed in the past...
2026-02-09 17:34:30,586 - src.bot.handlers - INFO - [vivek] Received message from user 485126821 (group=True): can you tell me what we have discussed in the past?
2026-02-09 17:34:30,586 - src.bot.handlers - INFO - [vivek] 🔍 Checking smart routing...
2026-02-09 17:34:30,588 - src.bot.handlers - INFO - [vivek] 🤖 Calling AI router...
2026-02-09 17:34:30,588 - src.bot.manager - INFO - [vivek] 🔍 should_respond_smart called for: 'can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,588 - src.bot.manager - INFO - [vivek] 🤖 Getting team router...
2026-02-09 17:34:30,588 - src.bot.manager - INFO - [vivek] 📨 Calling router.analyze_message...
2026-02-09 17:34:30,588 - src.bot.team_router - INFO - 📨 analyze_message called: chat=-1003716043040, msg='can you tell me what we have discussed in the past...'
2026-02-09 17:34:30,588 - src.bot.team_router - INFO - ⏳ Another bot is already analyzing this message, waiting...
2026-02-09 17:34:35,164 - src.indexing.search - INFO - [REDACTED] search found 10 results for: can you tell me what we have discussed in the past...
2026-02-09 17:34:35,164 - src.indexing.search - INFO - Built [REDACTED] context: 4157 chars, 4 chunks
2026-02-09 17:34:35,604 - src.bot.team_router - INFO - 📥 Got routing response: Let's analyze this message:
SHOULD_RESPOND: yes
PRIMARY: buddhi | CONFIDENCE: 0.9 | REASON: Direct request about past discussion requires curiosity a...
2026-02-09 17:34:35,604 - src.bot.team_router - INFO - 📊 Routing decision: should_respond=True, primary=buddhi, reason=Direct request about past discussion requires curiosity and exploration
2026-02-09 17:34:36,045 - src.agents.base - INFO - kopila: Using model gpt-4o-mini via openrouter
2026-02-09 17:34:36,485 - src.bot.team_router - WARNING - Brainstorm coordinator error: 'str' object has no attribute 'get'
2026-02-09 17:34:36,486 - src.bot.manager - INFO - [anita] 📊 Got decision: should_respond=True, primary=buddhi
2026-02-09 17:34:36,486 - src.bot.manager - INFO - [anita] ❌ Low-confidence secondary (0.30), not responding
2026-02-09 17:34:36,486 - src.bot.handlers - INFO - [anita] ❌ Not responding: Low confidence secondary: 0.30
2026-02-09 17:34:36,487 - src.bot.team_router - INFO - 💾 Got cached result after waiting: primary=buddhi
2026-02-09 17:34:36,487 - src.bot.manager - INFO - [jange] 📊 Got decision: should_respond=True, primary=buddhi
2026-02-09 17:34:36,487 - src.bot.manager - INFO - [jange] ❌ Not primary, assigned to buddhi
2026-02-09 17:34:36,487 - src.bot.handlers - INFO - [jange] ❌ Not responding: Assigned to buddhi
2026-02-09 17:34:36,487 - src.bot.team_router - INFO - 💾 Got cached result after waiting: primary=buddhi
2026-02-09 17:34:36,487 - src.bot.manager - INFO - [pakka] 📊 Got decision: should_respond=True, primary=buddhi
2026-02-09 17:34:36,487 - src.bot.manager - INFO - [pakka] ❌ Not primary, assigned to buddhi
2026-02-09 17:34:36,488 - src.bot.handlers - INFO - [pakka] ❌ Not responding: Assigned to buddhi
2026-02-09 17:34:36,488 - src.bot.team_router - INFO - 💾 Got cached result after waiting: primary=buddhi
2026-02-09 17:34:36,488 - src.bot.manager - INFO - [buddhi] 📊 Got decision: should_respond=True, primary=buddhi
2026-02-09 17:34:36,488 - src.bot.manager - INFO - [buddhi] ✅ I am the primary responder!
2026-02-09 17:34:36,488 - src.bot.handlers - INFO - [buddhi] ✅ Smart routing says respond: Primary responder: Direct request about past discussion requires curiosity and exploration
2026-02-09 17:34:36,489 - src.bot.team_router - INFO - 💾 Got cached result after waiting: primary=buddhi
2026-02-09 17:34:36,489 - src.bot.manager - INFO - [kalpana] 📊 Got decision: should_respond=True, primary=buddhi
2026-02-09 17:34:36,489 - src.bot.manager - INFO - [kalpana] ❌ Not primary, assigned to buddhi
2026-02-09 17:34:36,489 - src.bot.handlers - INFO - [kalpana] ❌ Not responding: Assigned to buddhi
2026-02-09 17:34:36,490 - src.bot.team_router - INFO - 💾 Got cached result after waiting: primary=buddhi
2026-02-09 17:34:36,490 - src.bot.manager - INFO - [vivek] 📊 Got decision: should_respond=True, primary=buddhi
2026-02-09 17:34:36,490 - src.bot.manager - INFO - [vivek] ❌ Not primary, assigned to buddhi
2026-02-09 17:34:36,490 - src.bot.handlers - INFO - [vivek] ❌ Not responding: Assigned to buddhi
2026-02-09 17:34:40,069 - src.memory.service - INFO - Retrieved 0 facts and 0 sessions for user 485126821
2026-02-09 17:34:41,917 - src.indexing.search - INFO - [REDACTED] search found 10 results for: can you tell me what we have discussed in the past...
2026-02-09 17:34:41,917 - src.indexing.search - INFO - Built [REDACTED] context: 4157 chars, 4 chunks
2026-02-09 17:35:47,726 - src.scheduler - INFO - Starting scheduled [REDACTED] indexing for: prashishh/...
2026-02-09 17:35:47,727 - src.indexing.sources.github_source - INFO - Fetching file tree from prashishh/...
2026-02-09 17:35:48,380 - src.indexing.sources.github_source - INFO - Found 819 files in repository
2026-02-09 17:35:48,402 - src.indexing.sources.github_source - INFO - Filtered to 62 indexable files
2026-02-09 17:35:48,402 - src.indexing.indexer - INFO - Starting indexing of 62 GitHub files (force=False)